 Our method achieves much faster speed. Specifically, for a video of 50 frames, our method runs 780 $\times$ faster than the state-of-the-art method RCVD.
Our method achieves much faster speed. Specifically, for a video of 50 frames, our method runs 780 $\times$ faster than the state-of-the-art method RCVD.
In this work, we present a data-driven post-processing method to overcome these challenges and achieve online processing. Based on a deep recurrent network, our method takes the adjacent original and optimized depth map as inputs to learn temporal consistency from the dataset and achieves higher depth accuracy. Our approach can be applied to multiple single-frame depth estimation models and used for various real-world scenes in real-time. In addition, to tackle the lack of a temporally consistent video depth training dataset of dynamic scenes, we propose an approach to generate the training video sequences dataset from a single image based on inferring motion field.
To the best of our knowledge, this is the first data-driven plug-and-play method (as of Feb. 2023)to improve the temporal consistency of depth estimation for casual videos. Extensive experiments on three datasets and three depth estimation models show that our method outperforms the state-of-the-art methods.

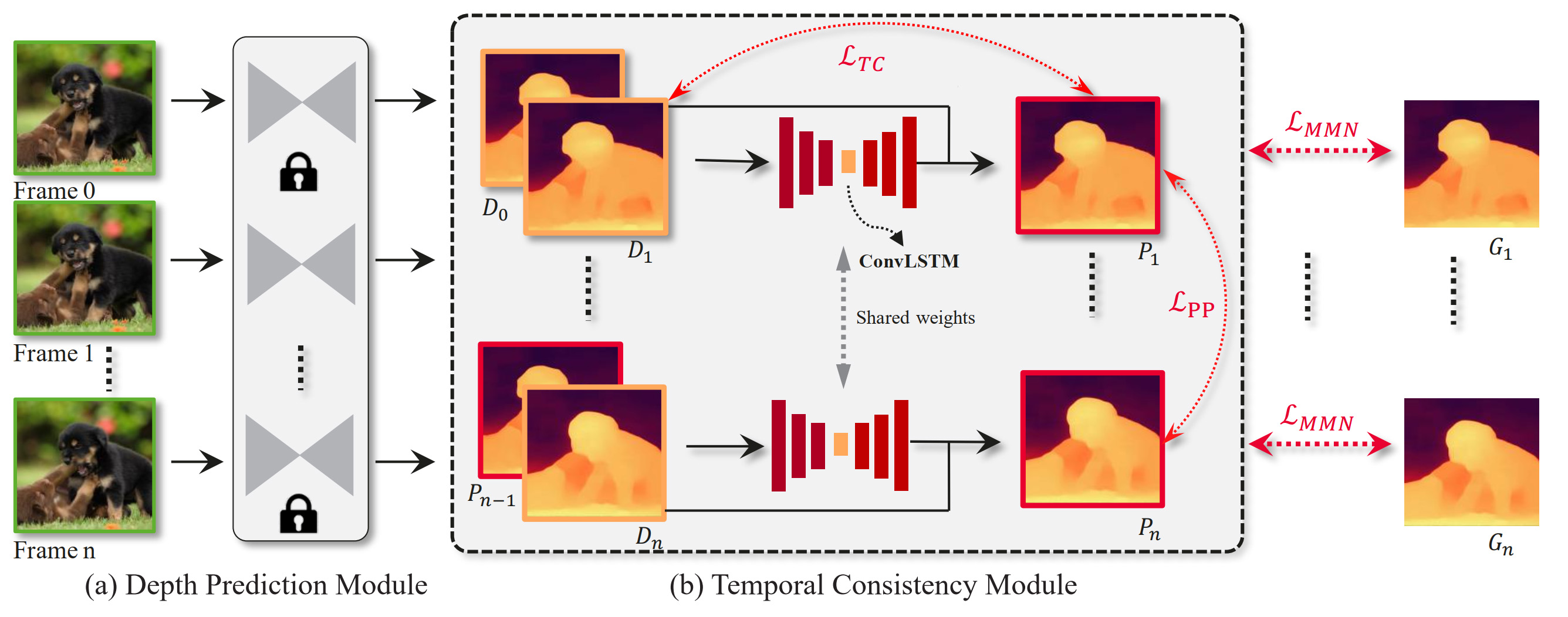
Method Pipeline. Our system takes the consecutive RGB frames as the input. We first estimate the initial depth map for each frame using a depth prediction module. Then, initial adjacent depth maps are fed into the temporal consistency module to predict consistent depth maps. During training, the depth prediction module is kept fixed, and we only train the temporal consistency module. At inference stage, our method takes ${D}_{n}$ and ${D}_{n+1}$ as input and output the consistent prediction depth of ${D}_{n+1}$. ${D}_{n}$ is the original depth maps, ${P}_{n}$ is the optimized consistent depth maps. ${G}_{n}$ is the ground truth depth maps.
Example of our video depth generation approach. (a) Segmentation mask predicted by Detectron2. (b) The optical flow predicted by a single frame. (c) The original frame and the next warped frame using (b). (d) The original depth map and the next warped depth map using (b).

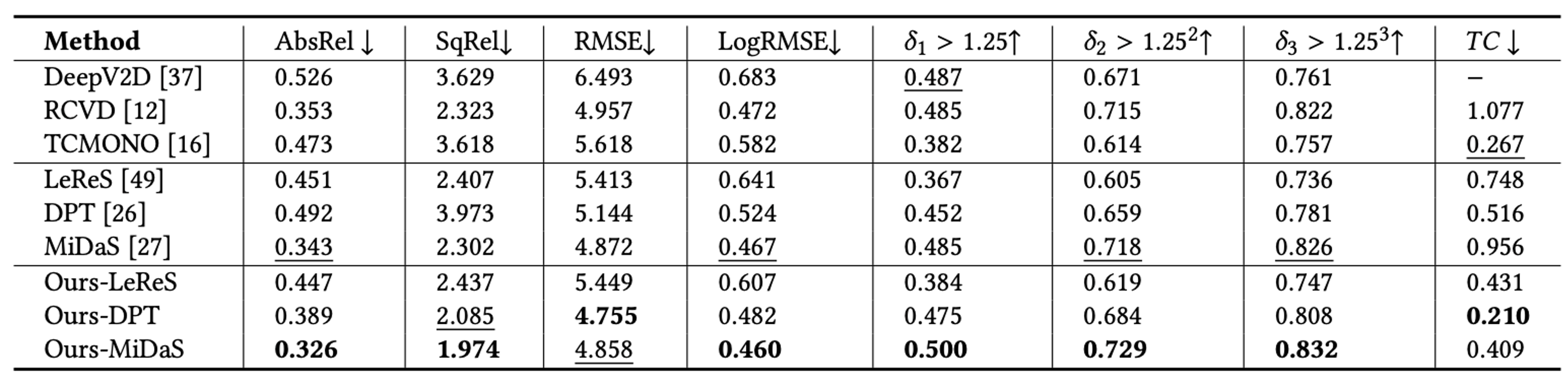
Quantitative comparison of depth on Sintel dataset. We evaluate three state-of-the-art single-frame depth prediction methods and three video depth prediction methods. Note that we don't evaluate the metrics of CVD as it fails to train on many sequences due to its reliability on COLMAP in estimating the camera pose. Our method improves the metrics of depth maps of all single-frame depth prediction methods. Compared with the methods aiming to produce consistent video depth, our method achieves state-of-the-art performance.
Many video special effects can be created with consistent video depth. Such as stable bokeh effect and insertion. Our method can be conveniently implemented for screen editing tasks.

Refer to the pdf paper linked above for more details on qualitative, quantitative, and ablation studies.
@inproceedings{li2023towards,
title={Towards Practical Consistent Video Depth Estimation},
author={Li, Pengzhi and Ding, Yikang and Li, Linge and Guan, Jingwei and Li, Zhiheng},
booktitle={Proceedings of the 2023 ACM International Conference on Multimedia Retrieval},
pages={388--397},
year={2023}
}